

还在等什么?赶紧跟着 Andrej 大神一起,揭开 LLM 的神秘面纱,成为 AI 时代的弄潮儿!
什么是大语言模型 (LLM)?
简单来说,LLM 是一种基于深度学习的人工智能模型。它们通过学习海量的文本数据,掌握了语言的规律,从而能够生成流畅、自然的文本。
你可以把 LLM 想象成一个超级“鹦鹉学舌”的高手。它不仅能记住你说过的话,还能根据上下文,预测你接下来可能要说什么。但这只“鹦鹉”可不简单,它“吃”进去的是整个互联网的知识! 更准确地说,LLM是在学习互联网文本的统计规律。
LLM 是如何“炼成”的?详解三阶段训练流程
LLM 的训练过程,就像一个孩子上学的过程,可以分为三个主要阶段:
1. 预训练 (Pre-training):海纳百川,构建知识基座这个阶段,LLM 会“阅读”巨量的文本,比如维基百科、新闻文章、书籍、论坛帖子等等——几乎整个互联网的公开文本数据!这就像我们在学校里学习各种基础学科,构建知识体系。
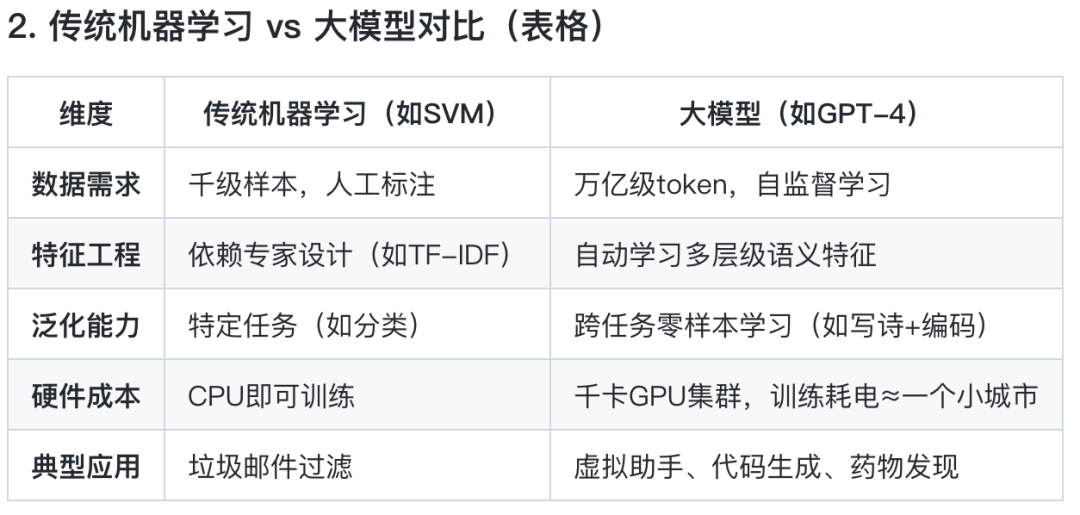
• 数据为王: • 海量数据: 训练 LLM 需要 TB 级别的数据。例如, FineWeb数据集就有 44TB!• 数据来源: Common Crawl等项目持续抓取互联网数据。• 数据清洗: 原始数据需要经过多重过滤,去除垃圾信息、有害内容、个人隐私等。
• 核心技术:Tokenization (分词) • 把文本切分成一个个小块(tokens),这可不是简单地按空格分开! • 字节对编码 (BPE): LLM 使用 BPE 算法,将常见的字母组合、单词甚至短语,都变成一个个独立的 token。 比如,“hello world” 可能会被分成 “hello” 和 ” world” 两个token,也可能因为大小写,空格数量不同而拆分不同。 • Token 数量: GPT-4 使用超过 10 万个不同的 tokens! • ticktokenizer网站: 强烈推荐!你可以亲自体验文本是如何被“切”成 tokens 的。• 序列长度的权衡: LLM能处理的上下文长度(即tokens数量)是有限的。 通过BPE,可以用更少的tokens表达同样的内容,提升效率。
• 核心技术:Transformer 神经网络 • 这是一种专门为处理序列数据(如文本)设计的神经网络。 • 注意力机制 (Attention): Transformer 的核心!它能让模型“关注”到句子中最重要的部分,理解上下文关系。 • 并行计算: Transformer 可以并行处理多个 tokens,大大加快了训练速度。 • 庞大的参数: 现代 LLM 通常有数十亿甚至数千亿个参数!
• 训练目标:预测下一个 Token • LLM 的训练就像一个“完形填空”游戏。给定一段文本,让模型预测下一个 token 是什么。 • 损失函数: 通过比较模型的预测和实际的下一个 token,计算一个“损失值”。 • 优化算法: 通过不断调整模型参数,让损失值越来越小,模型的预测越来越准。 • 算力怪兽: 预训练阶段需要消耗大量的计算资源,通常需要数千块 GPU 训练数月!
• 成果:基础模型 (Base Model) • 一个“知识渊博”但还不会“好好说话”的模型。 • 它能生成类似互联网文本的内容,但直接让它回答问题,效果往往不好。 • 知识的压缩: 可以把基础模型看作是互联网文本的“有损压缩”,它把海量知识“浓缩”到了模型的参数中。 • 复述 (Regurgitation): 基础模型有时会逐字逐句地“背诵”训练数据,特别是那些出现过很多次的内容。
2. 监督微调 (Supervised Fine-tuning, SFT):调教模型,学会好好说话预训练让 LLM “博览群书”,但要让它成为一个合格的助手,还需要“调教”。这个阶段,我们会给它看很多“对话范例”,就像老师给学生批改作业,手把手教它如何回答问题。
• 对话数据集: • 人工标注: 由人类标注员编写“对话范例”,包括各种问题和“标准答案”。 • 标注指南: OpenAI 等公司会制定详细的标注指南,告诉标注员如何写出“有帮助、真实、无害”的回答。 • LLM 辅助: 现在,越来越多的对话数据是用 LLM 生成,再由人工进行编辑和筛选,提高效率。 • 数据规模: 通常包含数十万甚至数百万个对话。 • 多样性: 数据集覆盖的话题越广,模型的泛化能力越强。
• 训练过程: • 继续预训练: 在 SFT 阶段,我们仍然使用预测下一个 token 的方法,但训练数据变成了对话数据集。 • 特殊 Tokens: 为了区分对话的不同角色(用户、助手),会引入一些特殊的 tokens,比如 [USER]、[ASSISTANT]。• 格式很重要: 对话数据的格式会影响模型的表现。不同模型可能有不同的格式规范。
• Token序列: 对话最终还是一维的token序列。 • 成果:助手模型 (Assistant Model) • 一个能够流畅对话、回答问题、提供帮助的模型,就像现在的 ChatGPT。 • 模仿人类: 助手模型本质上是在“模仿”人类标注员的回答风格和内容。 你和它对话, 实际上和人类标注员的“数字分身”对话。
3. 强化学习 (Reinforcement Learning, RL):自主探索,精益求精如果说 SFT 是“模仿”,那么 RL 就是“创新”。在这个阶段,LLM 不再依赖人类提供的“标准答案”,而是通过“试错”来自主学习,不断提升能力。
• 类比:做练习题 • 预训练: 学习课本知识。 • SFT: 研究例题和答案。 • RL: 自己做练习题,并对照答案,不断改进。
• 关键技术:试错学习 • 生成多个候选方案: 对于同一个问题,LLM 会生成多个不同的回答。 • 评分: • 可验证领域 (Verifiable Domains): 对于有明确答案的问题(如数学题),可以直接判断回答是否正确。 • 不可验证领域 (Unverifiable Domains): 对于没有明确答案的问题(如写诗、写笑话),需要人工评价或使用 奖励模型。
• 奖励与惩罚: 根据评分结果,对模型的参数进行调整。好的回答会得到“奖励”,差的回答会受到“惩罚”。 • 自我博弈: 在某些情况下(如 AlphaGo),LLM 可以通过“自己和自己下棋”来进行强化学习。
• 关键技术:来自人类反馈的强化学习 (RLHF) • 奖励模型 (Reward Model): 训练一个单独的神经网络,让它学习人类的偏好。 • 人类排序: 让人类对 LLM 生成的多个回答进行排序(例如,哪个笑话更好笑)。 • 训练奖励模型: 让奖励模型预测的结果与人类排序尽可能一致。 • 用奖励模型指导 RL: 使用训练好的奖励模型,代替人类进行评分,实现大规模的强化学习。
• 涌现的“思维”: • 思维链 (Chain-of-Thought): 在 RL 过程中,LLM 可能会“自发”地学会将复杂问题分解成多个步骤,逐步推理,就像人类思考一样。 • 自我反思: LLM 可能会“自言自语”,检查自己的答案,发现错误并进行修正。 • DeepSeek-Coder 论文: 展示了 RL 如何显著提升 LLM 的推理和解决问题能力。
• RLHF 的局限性: • 奖励模型并非完美: 它只是人类偏好的近似,可能会被“欺骗”。 • 对抗性样本: LLM 可能会生成一些看似高分、实则无意义的回答。 • 不能无限运行: RLHF 通常只能进行有限的迭代,因为时间长了,LLM 可能会“钻空子”。
• 成果:具备Reasoning能力的高级模型, • 典型模型:DeepSeek-Coder. • 可以进行复杂推理。
LLM 的“超能力”与“软肋”:更深入的剖析
LLM 很强大,但它们也有自己的“超能力”和“软肋”:
• 超能力: • 强大的知识储备: 它们“阅读”了海量的文本,掌握了丰富的知识。 • 流畅的语言表达: 它们能生成自然、流畅的文本,甚至可以写诗、写代码。 • 多任务处理能力: 它们可以处理各种各样的任务,从翻译到问答,再到创意写作。 • 情境学习 (In-context Learning): LLM 能够在对话过程中,根据上下文学习新的知识或技能。
• “软肋”: • 幻觉 (Hallucinations): 它们有时会“一本正经地胡说八道”,编造一些不存在的信息。 • 原因: 模型只是在模仿训练数据的统计模式,并不真正“理解”世界。 • 缓解: 训练模型识别自己的“无知”,或者让模型使用工具(如搜索引擎)获取外部信息。
• 缺乏常识?: 它们有时会犯一些“低级错误”,比如不知道 9.11 比 9.9 大。 (但这个例子存疑) • 计算与推理的局限: • 每个 Token 计算量有限: LLM 在生成每个 token 时,只能进行有限的计算。 • 需要“思维链”: 对于复杂问题,LLM 需要将推理过程分解成多个步骤,逐步进行。 • 不擅长心算: 最好让 LLM 使用代码解释器等工具来完成计算。 • 不擅长计数: 因为每个token的计算量有限。
• 拼写与字符操作的困难: • Tokenization 的影响: LLM 处理的是 tokens,而不是字母。 • 难以完成字符级任务: 比如反转字符串、提取特定位置的字符等。
如何与 LLM 愉快地“玩耍”?实用技巧分享
• 把它当作工具: LLM 是一个强大的工具,可以帮助我们提高效率,但不要完全依赖它。 • 检查它的工作: LLM 生成的内容可能包含错误,我们需要仔细检查。 • 清晰地表达你的需求: 越清晰、具体的提示 (prompt),LLM 的表现越好。 • 利用工具: 当涉及到计算、逻辑推理等任务时,让 LLM 使用工具(比如代码解释器、搜索引擎)。 • 提示工程 (Prompt Engineering): 通过精心设计 prompt,引导 LLM 生成更符合预期的结果。
LLM 的未来展望:无限可能
LLM 的发展日新月异,未来它们可能会:
• 多模态 (Multimodal): 不仅能处理文本,还能处理图像、音频、视频等多种类型的数据。 • 智能体 (Agents): 能够执行更复杂的任务,甚至可以自主完成一些工作,但仍需人类监督。 • 更个性化: 能够根据每个用户的需求和偏好,提供更个性化的服务。 • 持续学习: 不再局限于“一次性”训练,而是能够在与用户的互动中不断学习和进步。
在哪里可以体验 LLM?
• ChatGPT: https://chat.openai.com/ • Gemini: https://gemini.google.com/ • Claude: https://claude.ai/ (Anthropic 公司) • DeepSeek-Coder: https://chat.deepseek.com (擅长推理的模型) • Together.AI: https://www.together.ai/ (可以体验多种开源模型) • LM Studio: https://lmstudio.ai/ (可以在本地运行一些模型) • Hyperbolic: 适合体验基础模型。
持续关注 LLM 领域动态:
• LMSYS Chatbot Arena: 一个 LLM 模型排行榜,可以了解最新的模型及其性能。 • AI News Newsletter: 由 swyx 和朋友们维护,内容非常全面。 • X (Twitter): 关注 AI 领域的专家和大 V,获取最新资讯。
结语
LLM 是一个充满潜力的领域,它们正在改变我们的生活和工作方式。希望这篇文章能帮助你更好地了解 LLM,并与它们愉快地“玩耍”!
来源:草台AI



发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则