

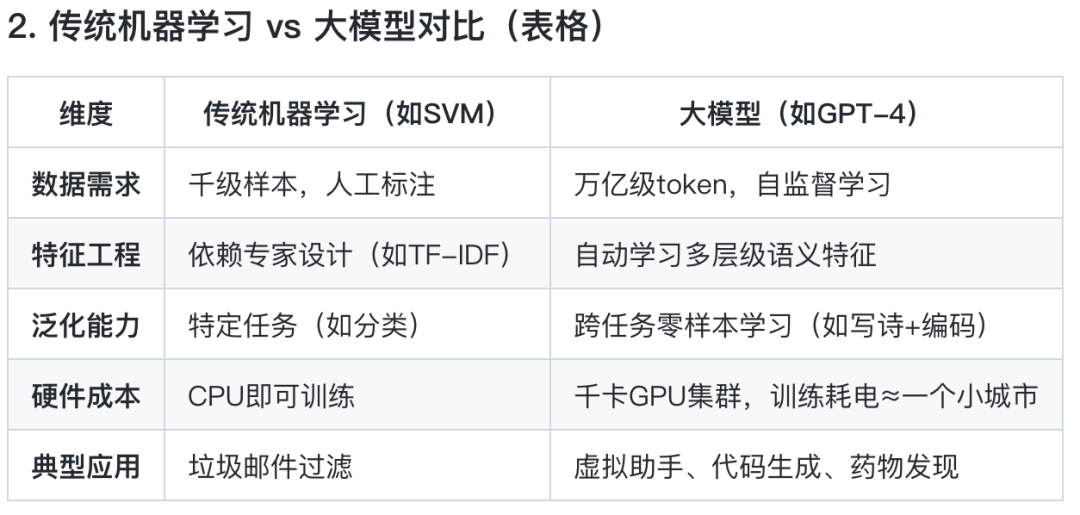
先解释一下什么是机器学习?机器学习的核心是什么?
机器学习的核心是:让机器通过数据自动学习规律,并具备处理新情况的能力。机器学习有三个核心点:
数据驱动:从大量数据中发现隐藏模式,而非依赖人工编写规则。
自动优化:用数学算法(如梯度下降)自我调整,逐步提升预测准确性。
泛化能力:学到的规律能应用到从未见过的新数据上,而非死记硬背。
机器学习的代表性模型有哪些呢?
1. SVM(支持向量机):通过核函数将数据映射到高维空间,寻找最优分类边界。
2. 随机森林(Random Forest):集成多个决策树,通过投票机制提升泛化能力。
但是机器学习也有他的局限性:
- 特征工程耗时且依赖领域知识,例如医疗文本处理需要医学专家标注关键术语。
- 模型无法自动学习数据中的抽象模式,例如图像中的复杂纹理或文本中的语义关联。

下一阶段—深度学习的爆发:从感知到认知(2012-2017)
技术的拐点是2012年AlexNet在ImageNet图像识别竞赛中夺冠(错误率15.3%,比传统方法降低10%以上),引爆深度学习浪潮。
比较具有代表的是卷积神经网络(CNN):通过局部连接与权值共享,高效提取图像空间特征。典型应用:人脸识别、自动驾驶中的物体检测。
循环神经网络(RNN)与LSTM:处理序列数据(如文本、语音),通过记忆单元捕捉长距离依赖。但RNN存在梯度消失问题,LSTM通过门控机制部分解决。
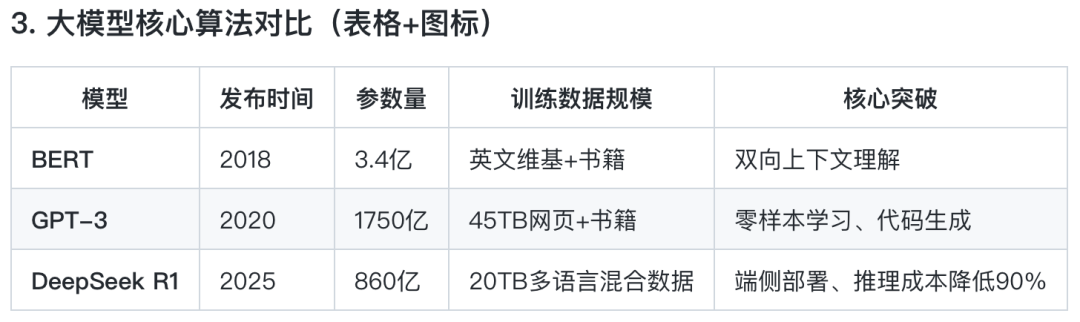
Transformer革命:重新定义自然语言处理(2017-2020)
2017年Google发表《Attention is All You Need》,提出Transformer架构,彻底取代RNN。
自注意力机制(Self-Attention):每个词计算与其他词的关联权重,自动捕捉上下文关系。例如“苹果”在“水果”和“公司”语境中动态调整含义。
位置编码(Positional Encoding) :通过数学函数为序列添加位置信息,解决传统RNN的顺序处理瓶颈。
2018年Google推出BERT(Bidirectional Encoder Representations),通过掩码语言模型(MLM)实现双向语义理解,横扫GLUE榜单。
GPT-1(2018)首次验证单向自回归语言模型的潜力,生成连贯文本。
大模型时代:算力、数据与算法的三重奏(2020-2022)
GPT-3的里程碑意义:
参数量达1750亿,训练数据涵盖45TB文本(包括书籍、网页、代码)。模型规模突破阈值后,自动获得零样本学习(Zero-Shot)、思维链(Chain-of-Thought)等能力。使用数千块GPU并行计算,需解决通信瓶颈(如NVIDIA的NCCL库优化)。构建高质量语料库,过滤重复、低质内容(如Common Crawl数据集的净化)。
OpenAI、Google(PaLM)、DeepMind(Gopher)形成第一梯队。
中国百度(文心)、智谱AI(GLM)跟进,但算力与数据规模暂处下风。
ChatGPT的破圈:从技术到产品的跨越(2022-2023)
InstructGPT框架:基于GPT-3.5,通过三阶段训练:
1. 监督微调(SFT):人类标注数万条高质量对话。
2. 奖励模型训练(RM):标注员对回答质量排序,训练打分模型。
3. 强化学习(PPO):模型根据RM反馈优化策略,对齐人类偏好。
中国力量的崛起:DeepSeek的技术突围(2023-2025)
DeepSeek的技术创新:通过知识蒸馏(Knowledge Distillation)将千亿参数模型压缩至百亿级,保持90%以上性能。
算法优化:稀疏注意力(Sparse Attention)减少计算量。
数据利用:合成数据生成(Synthetic Data)降低标注成本。
但是未来也面临很多挑战
1. 算力瓶颈:
– 训练GPT-5需约5万张A100 GPU,能耗相当于一个小型城市。
– 量子计算、存算一体芯片(如华为达芬奇架构)或成突破口。
2. 数据隐私:
– 欧盟《人工智能法案》要求大模型披露训练数据来源,中国推进数据分级分类管理。
3. AGI路径争议:
– OpenAI坚持“Scaling Law”(规模定律),DeepMind探索多模态融合(如AlphaFold 3)。
– 中国学者提出“以小博大”理论:通过算法补偿数据规模不足。
这场技术革命不仅是算法的迭代,更是人类认知边界的扩展。从SVM到ChatGPT,从GPU集群到国家级智算中心,每一个突破背后,都是数据、算力与人类智慧的共振。而DeepSeek的崛起,或许正预示着AI世界的下一个重心。
来源:人工智能训练营




发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则