

模型训练(Training)和推理(Inference)是深度学习中的两个核心过程。训练过程通过调整模型参数来优化模型性能,而推理过程则利用训练好的模型进行预测。
训练和推理在目标、过程、计算资源等方面存在差异。训练过程注重模型的参数调整和优化,需要大量的标注数据和计算资源;而推理过程则注重模型的预测能力,需要快速且准确地生成预测结果。
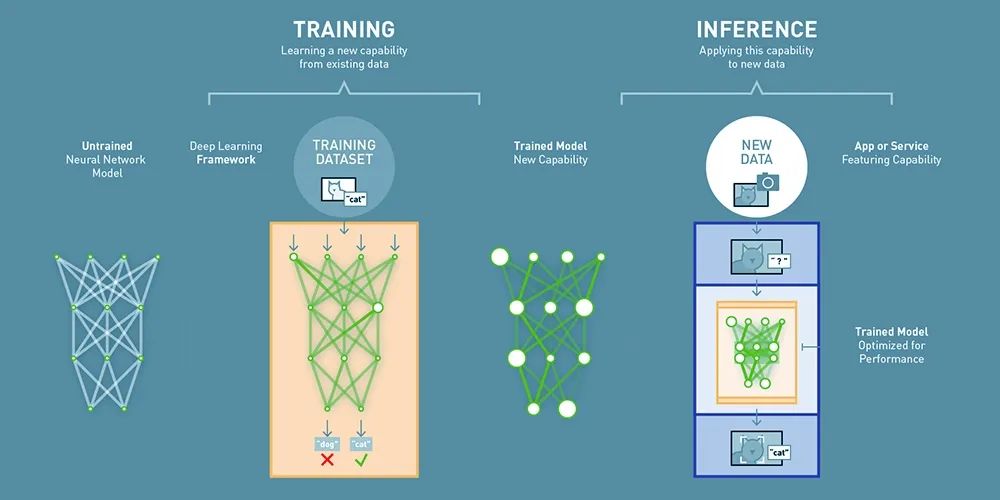
一、模型训练(Training)
什么是模型训练(Training)?模型训练是指利用一组已知的数据(通常称为训练数据)来教导或学习一个模型的过程。
在这个过程中,模型会尝试捕捉数据的内在规律和特征。一旦模型经过充分的训练(模型收敛),它就能够基于这些学到的规律对新数据进行准确的预测或分类。
大语言模型(LLM)的训练方法(Pre-training + Post-training)是什么?大语言模型的训练方法包括预训练(Pre-training)和后训练(Post-training)两阶段。
其中预训练为模型奠定了坚实的基础,使其具备较好的先验知识;而后训练则使模型更加适应特定任务或数据集,从而提高其性能和用户满意度。
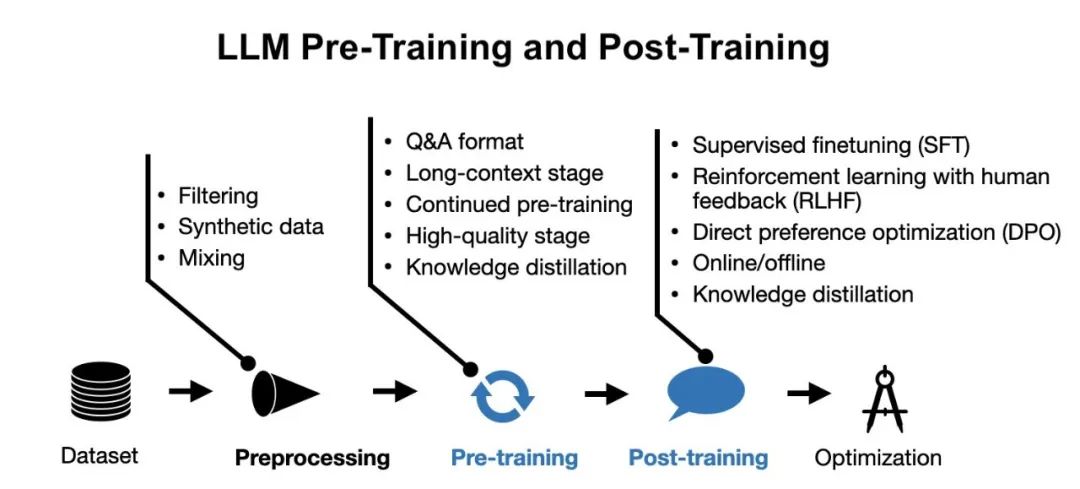
一、预训练(Pre-training)
预训练是在大规模无标注数据集上对模型进行的初步训练。这个阶段的目的是让模型学习到语言的普遍规律和特征,为后续任务提供坚实的基础。
预训练通常发生在模型开发的早期阶段,使用广泛的数据集,追求数据的多样性和规模。通过预训练,模型可以捕捉到语言的底层结构和模式,如词汇、语法和句子结构等,从而提高其泛化能力和表现力。
同时Hugging Face的Transformers库是一个功能强大的NLP库,它提供了对各种预训练模型的统一接口,支持PyTorch和TensorFlow框架,并包含了数千种可用于多种任务的预训练模型。
二、后训练(Post-training)
后训练是指在预训练模型的基础上,针对特定的任务或数据集进行的额外训练。这个阶段的目的是优化模型性能,使其更好地适应特定任务或数据集。
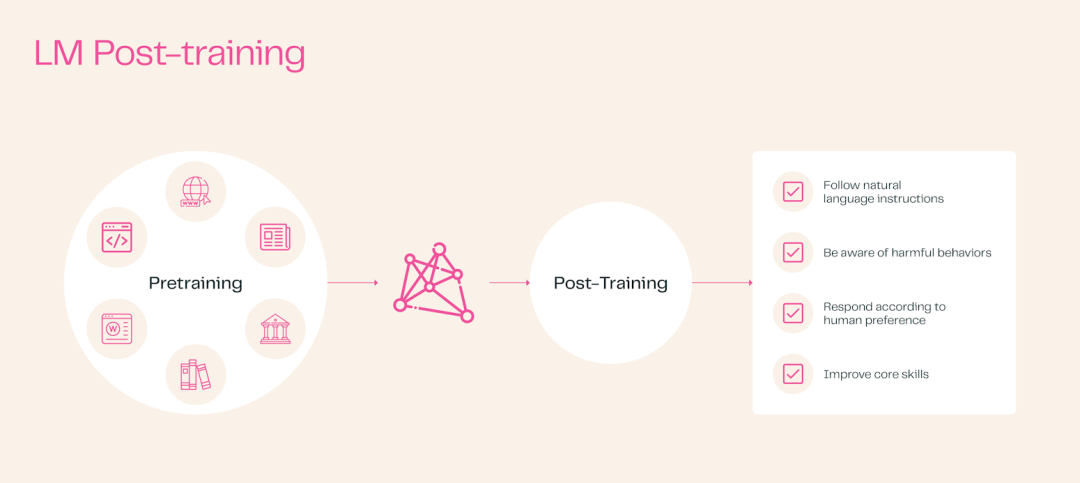
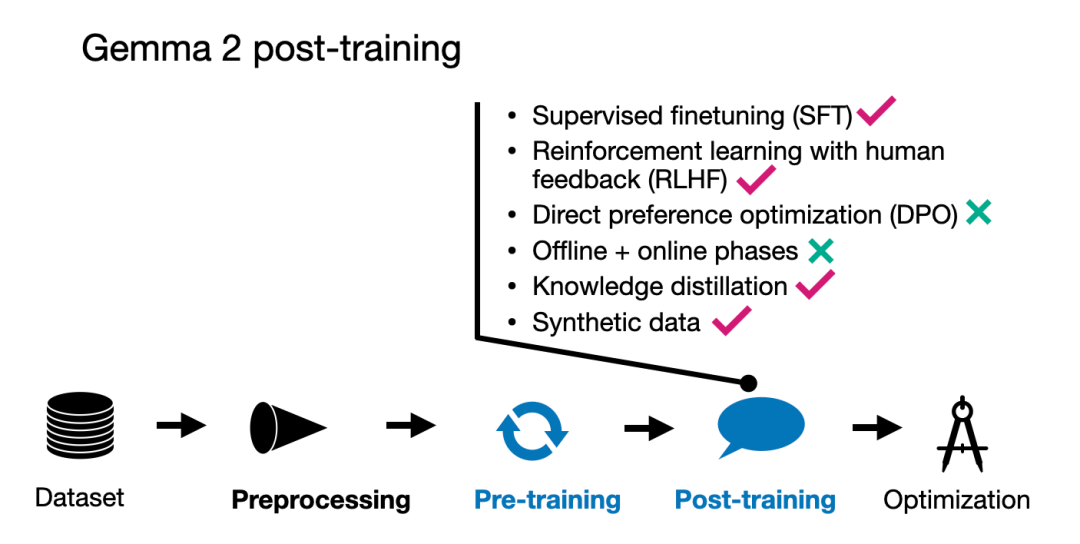
后训练通常发生在模型部署前或部署初期,后训练可以包括监督微调(Supervise Fine-tuning,SFT)、参数高效微调(Parameter-Efficient Finetuning, PEFT)和其他高级方法,如基于人类反馈的强化学习(RLHF)、蒸馏技术(Distillation)等。
二、模型推理(Inference)
什么是模型推理(Inference)?在模型训练完成后,使用训练好的模型对新数据进行预测或生成的过程。
在模型训练阶段,模型通过大量数据的学习,掌握了某种特定的能力或模式。而在推理阶段,模型则利用这种能力对新的、未见过的数据进行处理,以产生预期的输出。
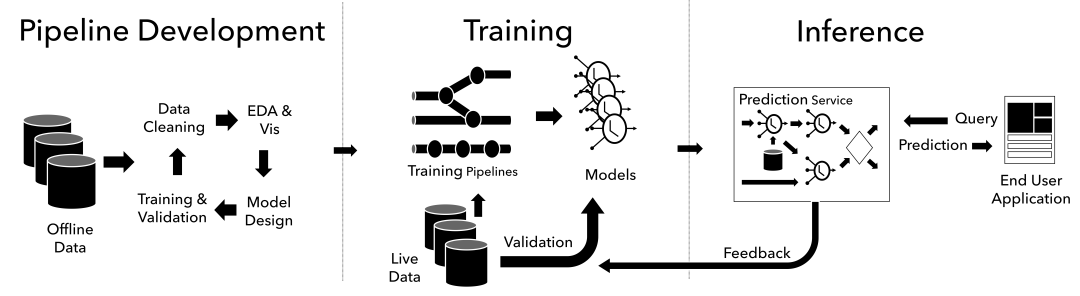
如何调用大语言模型(LLM)进行模型推理?训练好的大语言模型(LLM)需导出为可部署格式(如ONNX、PyTorch、TensorFlow模型文件),并保存模型权重和配置文件。在部署平台上加载模型后进行初始化,就可以开始进行模型推理。
Hugging Face设计了一种新的模型存储格式,如.safetensors,主要存储的内容为tensor的名字(字符串)及内容(权重),这种格式以更加紧凑、跨框架的方式存储模型数据,使得模型数据可以在不同的深度学习框架(PyTorch、TensorFlow)之间轻松迁移和使用。
来源:架构师带你玩转AI




发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则