


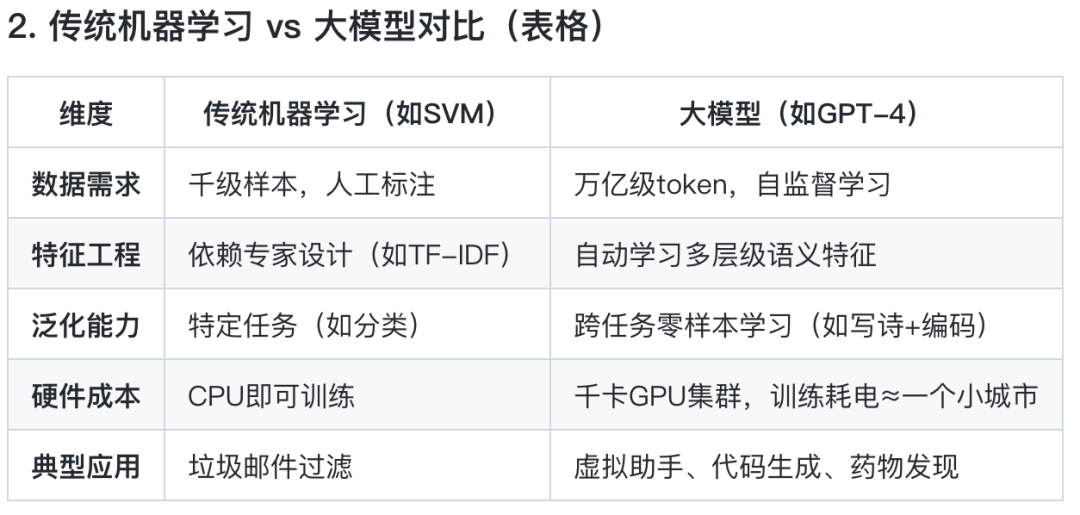
随着世界向更加多样化和整体化的数据处理转变,传统的检索增强生成(RAG)系统因仅限于文本数据而滞后。为了解决这个问题,多模态 RAG 系统应运而生,成为下一个重要的发展。这些系统使用文本、图像、表格等多种数据类型,并利用先进的多模态语言模型(LLMs)来提供上下文相关和准确的结果。
本文详细介绍了多模态 RAG 系统的架构、工作流程和实际实施,同时提供了使用 LangChain 和向量数据库等工具的见解。
什么是多模态 RAG 系统?
多模态 RAG 系统集成了多种数据类型,以提供强大的信息检索和综合能力。传统的 RAG 系统主要处理文本数据,限制了其在需要多模态洞察的场景中的有效性。然而,多模态 RAG 系统能够检测、解析和处理各种数据形式——文本、图像、图表、表格,甚至可选的音频或视频——从而提供更丰富的查询理解。
多模态 RAG 系统利用先进的模型,如 GPT-4o、GPT-4 Vision (GPT4-V) 和 LLaVA,高效地综合和检索信息。这些系统通过嵌入多模态能力来增强传统的基于文本的框架。
多模态 RAG 系统的组成部分
1. 多模态数据:
多模态数据是指文本、表格、图像、图表,有时还包括音频或视频的组合。这些数据类型被单独解析,处理成嵌入,并存储以供后续的检索和综合任务使用。
2. 多模态语言模型(LLMs):
先进的模型,如 GPT-4o 和 LLaVA,对于处理多模态数据至关重要。这些模型能够从文本和视觉输入中生成摘要和上下文洞察。
3. 文档加载器
像 unstructured.io 这样的工具从原始文档中提取和预处理文本块、图像和表格等元素。这些预处理的元素作为 LLM 的输入。
4. 向量数据库:
从多模态输入生成的摘要和嵌入使用像 OpenAI Embedders 的模型存储在向量数据库中。原始文档元素与这些摘要链接,以实现高效检索。
5. 多向量检索器:
这些检索器将摘要和嵌入映射到其各自的原始文档元素。通过使用共享文档标识符(doc_id),它们确保摘要与原始数据之间的无缝链接。
多模态 RAG 工作流程
为了更清晰地了解多模态 RAG 系统,让我们看看它们是如何工作的:
选项 1:多模态嵌入
应用嵌入模型,如 CLIP,联合嵌入文本和图像。
使用相似性搜索检索元素。
将原始文本和图像输入作为多模态 LLM 的合成输入。
选项 2:从视觉输入生成文本摘要
使用多模态 LLM 生成来自图像和表格的文本摘要。
将这些摘要存储在向量数据库中。
• 检索摘要并将其传递给标准 LLM 进行合成,排除原始视觉输入。
选项 3:综合摘要
• 使用多模态 LLM 为文本、表格和图像生成摘要。 • 将摘要与原始元素一起嵌入到向量数据库中。 • 检索摘要和原始元素,以使用多模态 LLM 进行答案合成。
推荐: 选项 3 特别适合涉及详细视觉数据(如图表和图形)的用例。
多向量检索器工作流程
多向量检索器工作流程构成了多模态 RAG 系统的基础。以下是其操作方式:
1. 数据提取:
使用像 unstructured.io 这样的工具从文档中提取和预处理文本、表格和图像。
2. 摘要生成:
将这些元素传递给 LLM,以创建详细摘要。
3. 存储:
将摘要及其嵌入保存在向量数据库中,将其链接到存储在单独文档数据库中的原始文档元素,使用共享的 doc_id。
4. 查询处理:
当用户提交查询时,多向量检索器使用相似性搜索识别相关摘要。
5. 上下文检索:
检索与摘要链接的原始文档元素(文本、表格、图像),并将其传递给多模态 LLM 进行答案合成。
这种方法确保即使对于复杂的多模态查询,也能提供精确和上下文丰富的响应。
多模态 RAG 架构
多模态 RAG 系统的架构集成了多个组件,以确保无缝的数据处理和检索:
1. 文档加载和预处理:
使用文档加载器,如 unstructured.io,提取文本、表格和图像。将 HTML 表格转换为 Markdown,以提高与 LLM 的兼容性。
2. 摘要生成:
使用多模态 LLM 为每个文档元素生成详细摘要。
3. 数据存储:
将摘要存储在向量数据库中,将原始文档元素存储在像 Redis 这样的文档数据库中。
4. 多向量检索:
使用公共文档 ID 连接摘要和原始元素。根据用户查询获取相关数据。
5. 答案合成:
使用多模态 LLM 根据获取的上下文生成答案,结合文本、表格和图像的信息。
与知识图谱的集成
多模态 RAG 系统中的一个新趋势是与知识图谱的集成。知识图谱提供结构化、互联的数据,丰富了系统的上下文理解。将多模态数据与知识图谱集成,使 RAG 系统能够连接不同的信息片段,揭示隐藏的关系,并提供更深入的洞察。例如,在医疗领域,一个与医学知识图谱集成的多模态 RAG 系统可以将患者症状、实验室结果和影像数据链接到相关的临床指南或研究,提供更准确的诊断和治疗建议。这种集成不仅提高了响应的质量,还使系统能够处理更复杂和相互关联的查询。
多模态 RAG 系统的优势
1. 改善上下文理解:
通过整合多种数据类型,多模态 RAG 系统提供更准确和全面的响应。
2. 可扩展性:
这些系统能够处理大型数据集,使其适合企业应用。
3. 灵活性:
该架构支持各种用例,从客户支持到数据分析。
4. 丰富的洞察:
多模态 RAG 系统利用先进的 LLM 从复杂的数据集中提取可操作的洞察。
构建多模态 RAG 系统的挑战
尽管好处显而易见,实施多模态 RAG 系统也面临挑战:
1. 复杂性:
管理多种数据类型并确保无缝集成需要仔细设计和强大的工具。
2. 数据预处理:
提取和格式化多模态数据元素可能需要大量人力。
3. 性能优化:
高效检索和综合多模态数据需要先进的索引和嵌入技术。
下一个重要问题将涉及这种系统的伦理部署。考虑到这些系统涉及多种类型的数据,偏见和数据隐私问题成为需要解决的挑战。开发人员需要实施适当的协议,以确保这些系统的公平性,并通过匿名化个人信息、避免对任何来源的过度依赖以及对这些系统进行持续审计以防止间接偏见。
一些实际应用
1. 医疗保健:
分析多模态患者数据,包括病历、影像报告和实验室结果,以进行诊断和个性化治疗计划。
2. 金融:
结合文本报告、财务表格和市场趋势图,以支持投资决策。
3. 教育:
通过将文本、视觉和表格集成到统一的知识检索系统中,创建互动学习平台。
4. 电子商务:
使用产品描述和图像的多模态嵌入增强产品搜索和推荐。
未来方向
多模态 RAG 系统的演变可能将重点放在以下几个领域:
1. 实时处理:
开发能够实时处理多模态数据的系统,以用于动态应用。
2. 先进模型:
引入前沿的多模态 LLM,以实现更复杂的理解和综合。
3. 伦理考虑:
解决多模态数据处理中的数据隐私和偏见等问题,以构建可信赖的系统。
结论
多模态 RAG 系统在信息检索方面代表了一个重大进步,通过整合多种数据类型提供前所未有的灵活性和准确性。通过利用 LangChain、向量数据库和先进的 LLM,这些系统为复杂查询提供丰富的上下文洞察。跨行业的潜在应用使它们成为当今数据驱动世界中的宝贵资产。
随着技术的进步,多模态 RAG 系统将继续重新定义我们处理和互动信息的方式,为 AI 驱动的解决方案开辟新的前沿。无论是在医疗保健、金融还是教育领域,它们连接多样数据形式的能力都承诺对全球行业产生变革性的影响。
来源:barry的异想世界



发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则