

老金不给大家聊Deepseek,转移一下注意力,碰巧有个新模型最近刚发布–Lumina Image 2.0。我们先来看下这个模型的介绍

从上图可以看到,Lumina Image 2.0模型具有2.6B的参数量,并且使用Gemma2作为分词器,使用的是FLUX的VAE模型,基本可以确定是属于FLUX的一个分支吧。
随后,Comfyui团队也在第一时间提供了相应的支持,免去大家装各种节点插件的烦恼,并且还非常贴心地为广大Comfyui使用者专门Repackage了Comfyui的专属模型。
我们来看下网址:
https://huggingface.co/Comfy-Org/Lumina_Image_2.0_Repackaged/tree/main/all_in_one
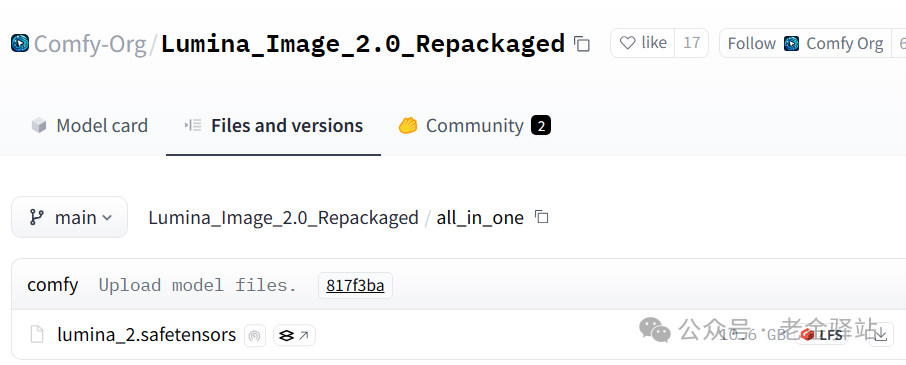
我们直接把模型下载后放入models/checkpoints目录下,注意不是以往的unet目录哦,别搞错了。
我们来看下工作流:
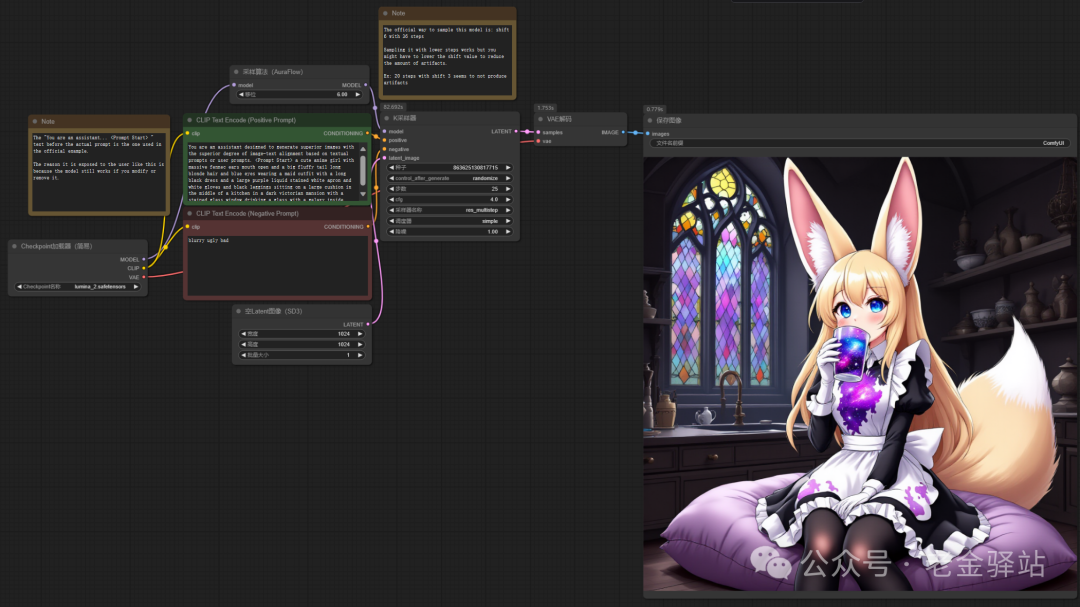
我们可以看到工作流非常简单,和基本的SDXL出图工作流差不多,只是多了一个Auraflow的采样算法节点。
这里,老金注意到,它的提示词写法和我们平时使用的不一样,我们一起来看下提示词的写法:
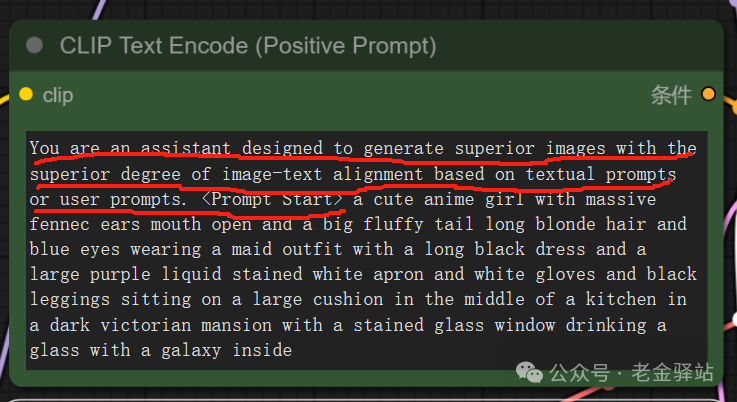
在正常的提示词前,还加了这一段设定。那这段设定有多重要呢?下面我们拿图来说,添加设定生成图像(左)和未添加设定生成的图像(右)的出图比较




从以上图像的比较,无论是从图像的细节表现,还是图像的美感,我们可以发现添加了设定提示词的明显要比未添加设定的好很多,看来大模型也会偷懒,所以,我们在提示词前面要把设定给加上!
Lumina Image 2.0模型还有一个不一样的地方,就是可以输入中文提示词,我们输入“一幅身穿汉服的中国传统美女近景半身肖像画背景有一个中国传统凉亭”,看下效果

很惊艳吧,这个模型还有一个优势就是出图快,老金测了一下基本比普通FLUX出图速度快一倍。
有兴趣的同学可以来试试哦!
最后,我们再一起欣赏一下Lumina Image 2.0模型出的美图吧。





最后,老金再啰嗦几句
- 要使用Lumina Image 2.0模型的话,需要升级你的comfyui到最新版本。
- Lumina Image 2.0模型支持中英文提示词输入,要提高出图质量,建议在提示词前添加一下内容:“You are an assistant designed to generate superior images with the superior degree of image-text alignment based on textual prompts or user prompts. <Prompt Start> ”
来源:老金驿站


发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则