

2025年1月20日,深度求索(DeepSeek)正式发布新一代通用模型R1,其综合性能直指OpenAI o1系列标杆。作为国产AI技术的突破性成果,R1不仅开源模型权重,更通过API开放思维链推理能力,引发行业对模型轻量化技术——知识蒸馏(Knowledge Distillation, KD)的深度关注。本文将从技术原理、应用价值及产业影响三个维度,解析这一支撑R1模型高效落地的核心技术。
一、知识蒸馏技术概述
知识蒸馏是由 Geoffrey Hinton 、Oriol Vinyals 和Jeff Dean 三位学者于 2015 年提出的一种模型压缩技术。其核心思想是通过将复杂的大模型(教师模型)的知识迁移到参数量更少、结构更简洁的小模型(学生模型)中,使得学生模型能够在保持高性能的同时,显著降低计算资源消耗并提升推理速度。
从本质上讲,知识蒸馏是一种知识迁移的过程,类似于人类教育中的“师徒传承”。教师模型通过大量数据的训练,掌握了复杂的模式和特征表达能力,而学生模型则通过学习教师模型的输出和推理过程,逐步掌握相关知识。这种迁移不仅包括显式的标签信息(硬目标),还包括隐式的概率分布信息(软目标),从而使学生模型能够更好地理解数据分布和推理逻辑。
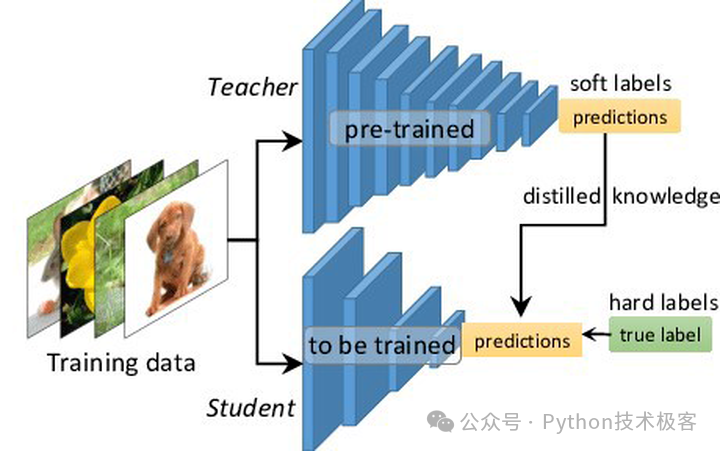
二、知识蒸馏的基本原理
知识蒸馏的实现过程可以分为以下几个关键步骤:
1. 教师模型与学生模型的准备
教师模型通常是经过大规模数据训练的复杂模型,具有较高的准确率和丰富的特征表达能力。常见的教师模型包括大型卷积神经网络(如 ResNet-101)、 transformer 架构(如 BERT 或GPT 系列)等。相比之下,学生模型的参数量和计算复杂度较低,通常采用较浅的网络结构或更简洁的模块设计。
2. 知识传递的过程
知识传递是蒸馏技术的核心环节,主要包括以下几个方面:
- 软目标的引入:不同于传统的监督学习仅关注标签信息(硬目标),知识蒸馏通过教师模型的输出概率分布(软目标)为学生模型提供更丰富的学习信号。例如,在图像分类任务中,教师模型不仅会输出“猫”的标签,还会提供各分类的概率分布(如“猫”80%,“狗”10%等),从而帮助学生模型理解更细微的特征差异。
- 损失函数的设计:蒸馏损失函数通常由两部分组成:
- KL 散度(Kullback-Leibler Divergence):衡量学生模型输出与教师模型输出之间的概率分布差异,迫使学生模型模仿教师模型的推理逻辑。
- 交叉熵损失:用于优化学生模型的分类性能,确保其对真实标签的预测准确率。
通过两者的结合,学生模型能够在保持分类性能的同时,更好地继承教师模型的知识。
3. 模型优化与训练
在训练过程中,学生模型通过最小化蒸馏损失函数不断调整自身参数,逐步逼近教师模型的推理能力。为了进一步提升蒸馏效果,还可以引入以下改进方法:
- 温度缩放(Temperature Scaling):通过调整教师模型输出的概率分布温度参数,使得软目标的分布更加平滑,从而增强学生模型的学习能力。
- 多阶段蒸馏:在某些场景中,可以采用多阶段蒸馏策略,先将大模型的知识迁移到中等规模模型,再逐步压缩至小型模型,从而实现更高效的模型压缩。
三、知识蒸馏技术的应用场景
知识蒸馏技术在 AI 领域的应用范围极为广泛,尤其是在资源受限的场景中,其优势尤为突出。以下是知识蒸馏技术的几个典型应用场景:
1. 模型部署与计算资源优化
在资源受限的环境中(如移动端设备、物联网设备等),直接部署大型模型往往面临内存不足、计算速度慢等问题。通过知识蒸馏技术,可以将大模型的知识迁移至轻量化的学生模型,从而实现模型的高效部署。例如,在智能手机上的图像识别应用中,经过蒸馏的学生模型可以在保持较高准确率的同时,显著减少计算资源消耗。
2. 推理速度与能效的提升
学生模型由于参数量较少,推理速度通常远快于教师模型。这一特点使其成为实时性要求较高的场景(如自动驾驶、实时语音识别等)的理想选择。例如,在自动驾驶系统中,经过蒸馏的模型可以在边缘设备上快速完成目标检测和路径规划任务,从而保证系统的实时性和可靠性。
3. 边缘计算与能效管理
在边缘计算场景中,设备通常面临严格的能耗限制(如无人机、智能手表等)。通过知识蒸馏技术,可以显著降低模型的推理能耗,从而延长设备的续航时间。此外,蒸馏技术还可以帮助优化模型的能效比,使其在资源受限的环境下实现更高效的计算。
四、 DeepSeek R1 模型中的知识蒸馏实践
DeepSeek R1 模型的成功发布,标志着国产 AI 技术在模型压缩与优化领域的重大突破。 R1 模型采用了先进的知识蒸馏技术,在保持高性能的同时,显著提升了模型的效率和可部署性。以下是 R1 模型中知识蒸馏技术的几个关键实践:
1. 教师模型的选择与训练
DeepSeek 在R1 模型的开发中,采用了经过大规模数据训练的复杂模型作为教师模型。通过多任务学习和数据增强策略,教师模型在多个基准测试中达到了行业领先水平,从而为知识蒸馏提供了扎实的基础。
2. 学生模型的设计与优化
在学生模型的设计中,DeepSeek 采用了轻量化网络架构,并结合自适应注意力机制,进一步提升了模型的推理效率。通过精心设计的蒸馏损失函数和多阶段训练策略,学生模型在继承教师模型知识的同时,实现了计算资源的显著优化。
3. 实际应用的验证
R1 模型在多个实际场景中得到了验证,包括图像识别、自然语言处理等。实验结果表明,经过蒸馏的学生模型不仅在性能上接近教师模型,而且在推理速度和能效方面表现优异,充分证明了知识蒸馏技术在实际应用中的价值。
五、总结与展望
知识蒸馏技术作为一种高效的模型压缩方法,为 AI 技术的普及和应用提供了重要支持。 DeepSeek R1 模型的成功实践,进一步验证了知识蒸馏技术在实际应用中的潜力。未来,随着 AI 技术的不断发展,知识蒸馏技术将继续在模型优化、边缘计算等领域发挥重要作用,推动人工智能技术的普惠化和智能化发展。
来源:Python技术极客



发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则