

DeepSeek-AI 提出的 DeepSeek-R1 引起了广泛关注,它通过创新的训练方法,在推理能力上取得了显著进展。今天,就让我们深入探讨一下 DeepSeek-R1 是如何训练的,以及其背后强化学习方法的重大意义。

一、DeepSeek-R1 的训练流程
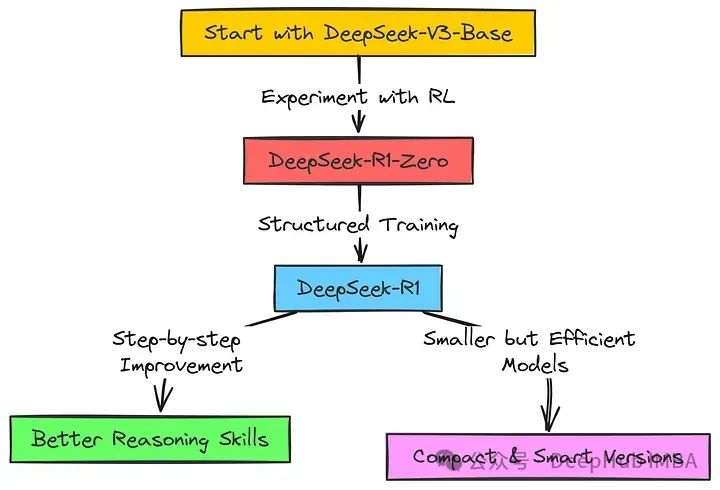
DeepSeek-R1 的训练并非一蹴而就,而是经历了一个复杂且精心设计的多阶段过程。整个训练流程可以分为以下几个关键阶段:
(一)冷启动阶段
在这一阶段,DeepSeek 团队收集了数千条长思维链(CoT)数据,对 DeepSeek-V3-Base 模型进行微调。这些数据主要聚焦于推理任务,涵盖了数学、逻辑、科学等多个领域。通过这种方式,模型能够初步建立起对推理任务的基本理解和结构化的输出模式。这一阶段的目标是为后续的强化学习阶段提供一个稳定且具有一定推理能力的基础模型。
(二)推理导向的强化学习阶段
在冷启动阶段的基础上,DeepSeek-R1 进入了推理导向的强化学习阶段。这一阶段的核心是利用强化学习(RL)算法,特别是群体相对策略优化(GRPO)算法,来进一步提升模型的推理能力。GRPO 算法通过采样多个可能的输出,并根据预定义的奖励函数对这些输出进行评估,从而优化模型的策略。奖励函数主要基于两个方面:一是准确性奖励,即模型输出的正确性;二是格式奖励,确保模型的输出符合特定的格式要求,如将推理过程放在特定的标签之间。通过这种方式,模型能够在大量的试错过程中学习到更有效的推理策略,并逐渐涌现出诸如自我验证、反思、长链推理等复杂行为。
(三)拒绝采样与监督微调阶段
当推理导向的强化学习阶段接近收敛时,DeepSeek 团队采用拒绝采样技术从当前的模型检查点生成新的训练数据。拒绝采样是一种从模型生成的大量样本中筛选出符合特定标准(如正确性和可读性)的样本的方法。这些筛选出的样本与 DeepSeek-V3 在写作、事实问答、自我认知等领域的监督数据相结合,再次对模型进行微调。这一阶段的目的是进一步优化模型的语言表达能力和通用任务处理能力,使其在非推理任务上也具备良好的表现。
(四)全场景强化学习阶段
在模型经过前几个阶段的训练后,DeepSeek-R1 进入了全场景强化学习阶段。这一阶段的目标是让模型在各种不同的任务场景中都表现出色,不仅包括推理任务,还包括写作、问答、翻译等通用任务。为此,DeepSeek 团队采用了基于规则的奖励模型和生成性奖励模型相结合的方式,对模型的输出进行全面评估。同时,为了确保模型的输出符合人类偏好,还引入了安全性评估,对模型生成的内容进行风险排查和优化。通过这一阶段的训练,DeepSeek-R1 在多个基准测试中取得了与 OpenAI-o1-1217 相当甚至更优的性能。
二、强化学习方法的意义
强化学习在 DeepSeek-R1 的训练中扮演了至关重要的角色,其意义主要体现在以下几个方面:
(一)突破传统监督学习的局限
传统的监督学习方法依赖于大量的标注数据,这些数据的获取往往耗时费力。而强化学习则通过模型与环境的交互,让模型在试错过程中自主学习,无需依赖大量的标注数据。DeepSeek-R1-Zero 作为纯强化学习训练的模型,证明了即使没有监督微调数据,模型也能够通过强化学习发展出强大的推理能力。这一突破为大型语言模型的训练提供了一种新的思路,降低了对标注数据的依赖,提高了训练的效率和可扩展性。
(二)激发模型的自主学习与创新能力
强化学习的核心在于让模型通过与环境的交互来学习最优的行为策略。在 DeepSeek-R1 的训练过程中,模型在强化学习阶段不断地尝试不同的推理路径和解决方案,并根据奖励信号进行自我调整和优化。这种自主学习的方式使得模型能够涌现出一些意想不到的推理行为和策略,如自我验证、反思等。这些行为和策略不仅提高了模型的推理性能,还为模型带来了更强的适应性和创新能力,使其能够在面对复杂问题时自主地探索和发现更优的解决方案。
(三)提升模型的泛化能力
强化学习的目标是让模型在各种不同的任务场景中都能表现出色,而不仅仅是针对特定的任务或数据集。通过在多个任务场景中进行强化学习训练,DeepSeek-R1 能够学习到更通用的推理模式和策略,从而在面对新的任务或数据时具有更强的泛化能力。这种泛化能力使得 DeepSeek-R1 不仅在推理任务上表现出色,在写作、问答、翻译等通用任务上也能够取得良好的性能,展现出了一种更加全面和通用的语言模型能力。
三、深度拆解训练过程背后的逻辑
DeepSeek-R1 的训练过程并非简单的线性流程,而是蕴含着深刻的逻辑和策略。以下是对这一训练过程的深度拆解:
(一)从零开始的探索与突破
DeepSeek-R1-Zero 的出现标志着 DeepSeek 团队对强化学习潜力的初步探索。通过直接在基础模型上应用强化学习,团队试图验证一个大胆的假设:是否可以通过纯强化学习来训练出具有强大推理能力的模型,而无需依赖任何监督微调数据。这一尝试不仅成功地证明了强化学习在提升模型推理能力方面的有效性,还为后续的训练方法提供了重要的参考和借鉴。DeepSeek-R1-Zero 的成功表明,模型在强化学习过程中能够自主地发展出复杂的推理行为和策略,为后续的训练工作奠定了坚实的基础。
(二)解决挑战与优化性能
然而,DeepSeek-R1-Zero 也暴露了一些问题,如可读性差、语言混杂等。这些问题限制了模型在实际应用中的可用性。为了解决这些问题,DeepSeek 团队引入了冷启动数据和多阶段训练策略。冷启动数据为模型提供了一个结构化的基础,使其在推理过程中能够生成更清晰、更易读的输出。多阶段训练策略则通过逐步优化模型的推理能力和语言表达能力,进一步提升了模型的性能。这种从问题出发,不断探索和优化的策略,体现了 DeepSeek 团队对模型性能的严格要求和对用户体验的高度重视。
(三)融合多种训练方法的优势
DeepSeek-R1 的训练过程融合了强化学习、监督微调等多种训练方法的优势。在推理导向的强化学习阶段,模型通过与环境的交互学习到了强大的推理能力;在拒绝采样与监督微调阶段,模型利用高质量的监督数据进一步优化了语言表达能力和通用任务处理能力;在全场景强化学习阶段,模型在多种任务场景中进行训练,提升了泛化能力和与人类偏好的一致性。这种融合多种训练方法的策略,使得 DeepSeek-R1 能够在推理任务和通用任务之间取得良好的平衡,展现出了一种更加全面和通用的语言模型能力。
(四)持续迭代与优化
DeepSeek-R1 的训练过程并非一成不变,而是一个持续迭代和优化的过程。在每个阶段,团队都会根据模型的表现和存在的问题,对训练方法和策略进行调整和优化。例如,在推理导向的强化学习阶段,团队引入了语言一致性奖励来解决语言混杂的问题;在拒绝采样与监督微调阶段,团队通过精心设计的训练数据和微调策略,进一步提升了模型的性能。这种持续迭代和优化的策略,使得 DeepSeek-R1 能够在不断变化的环境中保持竞争力,持续提升模型的性能和质量。
四、总结与展望
DeepSeek-R1 的训练过程是一次大胆的尝试和创新,它通过精心设计的多阶段训练策略和强化学习方法,成功地提升了模型的推理能力。DeepSeek-R1-Zero 作为纯强化学习训练的模型,证明了即使没有监督微调数据,模型也能够通过强化学习发展出强大的推理能力。DeepSeek-R1 则通过引入冷启动数据和多阶段训练策略,进一步优化了模型的性能,使其在多个基准测试中取得了与 OpenAI-o1-1217 相当甚至更优的性能。
来源:智驻未来


发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则